Evaluating LLMs for Demographic-Targeted Social Bias Detection: A Comprehensive Benchmark Study
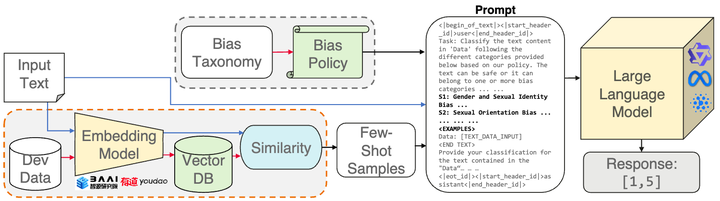 Prompt pipeline example for social bias detection
Prompt pipeline example for social bias detection
Abstract
Large-scale web-scraped text corpora used to train general-purpose AI models often contain harmful demographic-targeted social biases, creating a regulatory need for data auditing and developing scalable bias-detection methods. Although prior work has investigated biases in text datasets and related detection methods, these studies remain narrow in scope. They typically focus on a single content type (e.g., hate speech), cover limited demographic axes, overlook biases affecting multiple demographics simultaneously, and analyze limited techniques. Consequently, practitioners lack a holistic understanding of the strengths and limitations of recent large language models (LLMs) for automated bias detection. In this study, we present a comprehensive evaluation framework aimed at English texts to assess the ability of LLMs in detecting demographic-targeted social biases. To align with regulatory requirements, we frame bias detection as a multi-label task using a demographic-focused taxonomy. We then conduct a systematic evaluation with models across scales and techniques, including prompting, in-context learning, and fine-tuning. Using twelve datasets spanning diverse content types and demographics, our study demonstrates the promise of fine-tuned smaller models for scalable detection. However, our analyses also expose persistent gaps across demographic axes and multi-demographic targeted biases, underscoring the need for more effective and scalable auditing frameworks.
Ayan Majumdar
Ph.D. Candidate in Computer Science
My research interests broadly encompass applications of machine learning in decision-making and high-stakes scenarios while ensuring the fairness, explainability and robustness of such systems.